总结
之所以放前面是因为正文部分写的比较乱。
做这个功能让我想起刚毕业的一次面试问题,问题是“如何实现搜索功能”,当时的回答大概是根据关键字遍历数据集然后提取匹配到记录等等,反正现在想来回答是很水的。说这个的重点不是面试,而是想说说自己心态的改变。
毕业找工作:工作经验?不存在的。道理我都懂,给我点时间我什么都能做。
现在:工作经验?存在的。没实际的写过一些东西,不踩过一些坑,怎么可能成长起来。比如开发过这个搜索功能,有过权重的计算方式,知道自己还可以改进的地方,能够更快更好的开发这个功能,哪怕需求有变动,掌握了原理的东西,就可以明月照大江。
这篇文章本来7月份就该写了的,但是一直没静下心来。这两个月工作任务倒是不重,主要空余时间放在巩固基础上了。
前端的东西确实比较多,H5、CSS3,ES6新增的东西到现在还没都用一遍,这些也是现在前端的基础吧,虽然有些用的少+浏览器兼容问题,但是知道总比不知道好很多。还有各种的框架、webApp要走的路还很长....
目前在干的事: node.js、webApp、vue.js、
nodejs从爬虫上手的,目前爬了教学式的豆瓣电影、BOSS直聘的招聘信息、xiciIP的代理IP,也放在自己的github上面了,后面会写关于爬虫的东西。
另外...自己的写作水平还需要提高啊,有些东西总感觉没说清晰,有没看懂的部分可以留下评论,我会认真回复的。
正文
先看UI的设计图。
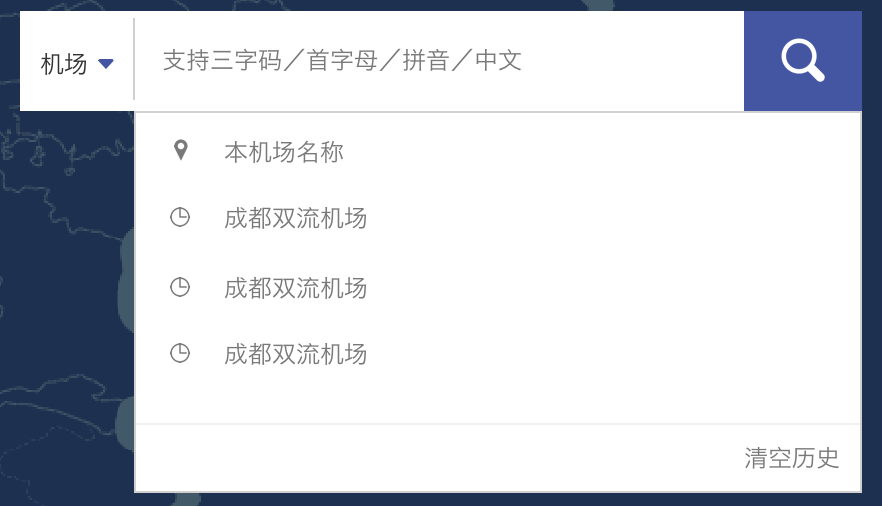

当然还有后续的功能,但是针对搜索框开发,所以就不谈后续了。
首先说说主要的技术点和经验,因为开发的时候先做的这个东西
1.关于原生select
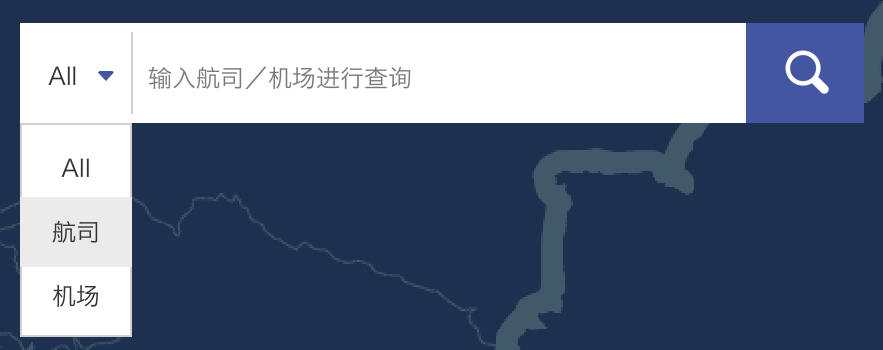
由于原生select中,option只能修改部分样式,不能完全达到图中的效果,故果断放弃,采用div+ul和绝对定位对其进行模拟。
2.历史搜索记录
要求:1.保存用户搜索记录;2.点击空白状态的文本框时显示记录;3.最多8条,排序以最近搜索为先;4.提供清除。
思路:
1.保存记录--每次搜索一个正确数据之后,由于结构固定且有排序操作,采用数组searchHis存取,将该数组Stringify后存入localStorage.
2.点击显示--文本框绑定事件,在keywords为空的时候取出searchHis,再显示到页面中.
3.最多8条 有排序--属于先进先出,典型的队列操作,用数组的unshift实现头部插入,然后判断length>8?length=8:不变,length置8即把尾部多余的删去.
4.提供清除--目前是做的清除所有,也就是localStorage.removeItem删除。若是删除指定某记录,则先取出searchHis,然后删除该条后重新放入localStorage
再来说踩过的坑,算是自己不够仔细,
bug:由于localStorage是针对网站x存储的,故同一浏览器登录x的所有用户都可以取出该记录,相当于一台电脑上同一浏览器登录的用户共享一个记录...
解决办法:在命名时候针对当前登录用户做标识。
3.搜索匹配的权重计算+匹配字符添加样式
这个功能打算单独提出来再仔细说,先放权重计算的思路。
此搜索功能可根据输入的汉字、拼音、代码(英文+数字)、拼音首字母 对机场a[ ]、航司b[ ]进行查询,相当于输入英文要匹配3组数组,故中文可以直接匹配,所以权重计算针对英文。
在结果集优先显示机场,然后航司,所以先匹配机场的数据源push到结果集,再匹配航司,可以解决优先显示的问题。
匹配规则:拼音首字母>代码>拼音,
一开始设计匹配方法的时候,直接匹配到了就提取,没有加入权重计算,故每次匹配会被数据源a[],b[]本身的数组序列影响结果,
用机场数据举例:
a[0]==={
qp: 'chengdushuangliu', zn: '成都双流', code: 'CTU', sp: 'CDSL' } a[99]==={ qp: 'hangzhouxiaoshan', zn: '杭州萧山', code: 'HGH', sp: 'HZXS' }
这时候输入H,则搜索结果中会这样显示:
chengdushuangliu...
hangzhouxiaoshan...
因为在遍历的时候先从a[0]中找到了cheng,就push到结果集中进行a[1]匹配,这样明显与优先匹配拼音首字母要求不符合,先看看原来的代码
if(vval.py.toLowerCase().indexOf(word)> -1 ){//拼音
return r.push(vval);}
if(vval.code.toLowerCase().indexOf(word)> -1 ){//代码 return r.push(vval); } if(vval.airportName.indexOf(word)> -1 ){//中文 return r.push(vval); } if(vval.pinyin.toLowerCase().indexOf(word)> -1 ){// return r.push(vval); }
解决思路:在外层添加一个counter,用于记录匹配次数,然后根据匹配次数对数据集进行排序。在循环外层声明一个二维数组nr[ [ ], [ ], [ ], [ ], [ ] ],用于存放不同权重的结果。
新代码:
let counter = 4; if(vval.py.toLowerCase().indexOf(word)> -1 ){ counter --; nr[counter].push(vval); } if(vval.code.toLowerCase().indexOf(word)> -1 ){ counter --; nr[counter].push(vval); } if(vval.airportName.indexOf(word)> -1 ){ counter --; nr[counter].push(vval); } if(vval.pinyin.toLowerCase().indexOf(word)> -1 ){ counter --; if(vval.pinyin.toLowerCase().indexOf(word) == 0){ //如果匹配到为拼音首字母则优先显示 counter --; } nr[counter].push(vval); }
最后把nr[0-4]合并,就可以把权重高的放在前面了,这也是代表权重的counter为什么是--的原因。